




|
| |
|
|
|
|
|
TCHS 4O 2000 [4o's nonsense] alvinny [2] - csq - edchong jenming - joseph - law meepok - mingqi - pea pengkian [2] - qwergopot - woof xinghao - zhengyu HCJC 01S60 [understated sixzero] andy - edwin - jack jiaqi - peter - rex serena SAF 21SA khenghui - jiaming - jinrui [2] ritchie - vicknesh - zhenhao Others Lwei [2] - shaowei - website links - Alien Loves Predator BloggerSG Cute Overload! Cyanide and Happiness Daily Bunny Hamleto Hattrick Magic: The Gathering The Onion The Order of the Stick Perry Bible Fellowship PvP Online Soccernet Sluggy Freelance The Students' Sketchpad Talk Rock Talking Cock.com Tom the Dancing Bug Wikipedia Wulffmorgenthaler |
|
bert's blog v1.21 Powered by glolg Programmed with Perl 5.6.1 on Apache/1.3.27 (Red Hat Linux) best viewed at 1024 x 768 resolution on Internet Explorer 6.0+ or Mozilla Firefox 1.5+ today's page views: 101 (16 mobile) all-time page views: 3394018 most viewed entry: 18739 views most commented entry: 14 comments number of entries: 1226 page created Fri Jul 4, 2025 09:44:15 |
|
- tagcloud - academics [70] art [8] changelog [49] current events [36] cute stuff [12] gaming [11] music [8] outings [16] philosophy [10] poetry [4] programming [15] rants [5] reviews [8] sport [37] travel [19] work [3] miscellaneous [75] |
|
- category tags - academics art changelog current events cute stuff gaming miscellaneous music outings philosophy poetry programming rants reviews sport travel work tags in total: 386 |

| ||
|
- when Strength and Respect (from Influence) are comparable, Strategy becomes the deciding factor! (the triptych was intentional, if it hasn't been noticed) - TRUMP's The Art of Deal, Chapter II - Trump Cards [N.B. In the following case (and others), the "want" is something like not being a smoking hole in the ground.]  One supposes they didn't read The Art of Deal! [Hint: are there any other deadlines coming due soon?] (Source: bloomingbit.io) Considering that the original I Ching is also known as the Book of Changes, the updated and improved The Art of Deal can naturally be rendered as the Book of Exchanges (because what is a Deal, but an Exchange)? These exchanges have indeed been coming hard and fast, with an initial change on X preceding Musk's (latest) apology to GEOTUS (and a rebound of TSLA to over US$320). That would pale in comparison to what next happened in the Middle East, though, as the Rising Lion (of Judah; the eschatological angle will be explored in Twilight Struggle: New Moon, in the future) battered Iran, decapitating much of their military and scientific leadership. This left the ever-merciful Lion of America to extend an olive branch, but alas, one expects this age-old feud to continue playing out. Now, while the description of The Art of Deal as the successor to The Art of War as made in the previous post was partly tongue-in-cheek, a closer examination suggests that the proposition is more plausible than it might appear at first sight. Sun Tzu's introduction to stratagems began by asserting that to destroy something (i.e. in War) is always inferior to obtaining it whole and undamaged - which is exactly the realm of... Deals. What fortune it is, then, for America to be led by the consummate Dealmaker, once praised in less-bipartisan and more-objective times by the Chicago Tribune as "[being] a deal maker the way lions are carnivores and water is wet"! Know Thy Self, Know Thy - Sun Tzu's The Art of War, Chapter III - Attack By Stratagem Since this exposition has been some time in the making, let's recap what has brought us to this. It began in early February, when the strategic move by GEOTUS to tariff "China, the European Union and (all) the rest" was predicted two months in advance, together with America's refusal to become a sucker with regards to the Ukraine war, as well as their following bid for Russia. The post on Strength then explained the preliminary effects of the universal tariffs (i.e. a bunch of countries suddenly being open to negotiations), with the true meaning behind the tariffs (i.e. a proclamation of [continued] American primacy) then revealed, a month after their imposition. Given that it's more or less two months after the original tariffs, with about a single month remaining to T-Day (July 8th for Europe and most of the world, still August 12th for China... for now), a second update is in order. This then calls for additional revelations to establish background context (and explain why America is acting as it has), and today's Very Hard Truth is: AMERICA HAS NOT BEEN, UH, WINNING. There. Simple as that.  Different charts, quite different stories (Sources: economist.com [top], worldeconomics.com [bottom]) This fact has in fact been raised here back in September 2023, with reference to national Production. In short, China's GDP (in real PPP terms) had already exceeded the U.S. a decade ago and is currently some 20% larger, with the gap projected to only continue widening. Had it not been for a (slightly-suspicious) Pandemic Game starting back in 2020, this deficit (from the U.S. perspective) would likely be rather larger today. On the other hand, Team Blue outlets (such as The Economist) tend to present GDP statistics in U.S. dollar terms instead, which has China maxing out at 75% of the U.S. economy about 2021, before dropping back to 60-odd percent. While commentators have largely decried Amerika's new (and tougher) methods, this is mostly putting the cart before the horse, in confusing cause and effect. The essential question, from which all else springs, is: Does America want to continue being Number One? This had been raised by a distinguished professor at the LKY School of Public Policy back in September last year (also published in Foreign Policy), and more or less advises the U.S. to just lie down and allow others to surpass them, because "...once you give up on the obsession* with being No. 1, your engagement with China no longer needs to be confrontational**". One supposes TRUMP (and LKY, were he still alive) might have some choice words about that! Now, working backwards from the (pretty safe) assumption that Amerika does want to remain #1, one can begin to understand why TRUMP (and his administration) have been acting as they have. While the LKYSPP dean continues with "Do you know what will happen to the American people's way of life and the U.S. system of government if you become No. 2? Absolutely nothing.", one suspects that, at some level, he should realise that this is clearly not the case. To begin with, if becoming Number 2 entails the U.S. dollar no longer being the (major) global reserve currency, this would very probably force interest rates to increase, devalue the dollar, and (significantly) lower the American standard of living.  [Translation: The world of international relations was always anarchic. As to how Big Brother Uncle Sam imposed order, it was not through "principles"***, but through his fists! Whenever any country did not submit (ref: the U.S.S.R., Iran, Iraq, Afghanistan, too many Latin American nations to count), he whacked them! Bro was definitely the greatest gangster of the seven seas!] (Source: manhuagui.com) And we're not even getting into the military/security angle yet. Discounting fevered dreams of Global Thermonuclear War (given that Russia has more nuclear warheads than the U.S. currently, with China making haste to catch up), the ongoing Team Red vs. Team Blue proxy wars in Ukraine and the Middle East have reinforced that there is really no substitute for production, where it comes to prevailing in such conflicts. While Team Blue has generally played up their supposed technological edge in homefront propaganda, it remains that (just a portion of) North Korea's artillery shell output has allowed Russia to remain on the offensive in Ukraine, with almost all of the 31 upgraded M1A1 Abrams tanks that the U.S. gifted Ukraine, already destroyed (or worse, captured). Further south, Iranian ballistic missiles have overwhelmed Israeli air defences in Tel Aviv and elsewhere, so one can only imagine the outcome if Iran had twice, five times or ten times the amount of launchers and missiles to spare! Given this, TRUMP's clarification on his tariff policy being intended to have the U.S. manufacture more tanks and tech, and not sneakers and T-shirts, makes plenty of sense. This as it happens is also why he's not entirely happy at Apple moving production to India (even if that's preferable to it remaining in China, from the U.S. perspective), since one figures that the ability to manufacture and assemble high-end computing and communications devices (like iPhones) is in fact relevant to modern war efforts. While the latest issue of The Economist claims a "manufacturing delusion" in dismissing the impact of subsidies (or tariffs) towards national security, it appears very much a problem when the entire U.S. builds just five (5) commercial vessels annually, with China having literally 200 times (not percent, times) the production capacity. [To be continued...] [*Interestingly, obsession happens to be a trait associated by TRUMP with success, in The Art of Deal.] [**Here, one might muse at why the good professor did not instead address China, and inform them that they simply have to be content with remaining Number 2. This would certainly defuse mutual tensions with the U.S. too!] [***Or, as Teddy Roosevelt was wont: Speak softly and carry a big stick; alas, the stick is simply not as large as in previous eras, thus GEOTUS attempting to make it up with strategy.]
It certainly didn't take long at all for a bunch of events hinted at from the June 4th blog entry to transpire, beginning with a relatively innocuous dissent by Elon Musk on the One Big, Beautiful Bill mere hours after it was posted. That, as it turned out, was taken by TRUMP as a challenge, and a few provocative (and now deleted) X-es by Musk later, the saga ended with GEOTUS wishing Musk well, but not wishing to communicate further with him, at the present moment. Considering that the Tesla founder had reportedly engaged in some nonconsensual amateur mixed martial arts (which, recall, he has been training in) with Treasury Secretary Scott Bessent, he was fortunate not to have landed behind bars here, with GEOTUS once again demonstrating his characteristic (and very non-LKY-like) mercy - before making a surprise appearance at UFC 316. His fist-pumping to renowned adopted gay anthem YMCA (surely?) might then have been a show of solidarity with (the increasingly-unrecognized) Pride* Month, or perhaps his unwittingly-mauled Treasury Secretary. So much inclusiveness! Musk's departure from the scene would quickly be followed by riots in Los Angeles, stemming from a (completely legal and justified) raid by Immigration and Customs Enforcement (ICE) officers... which somehow developed into a spate of mostly-peaceful conflagrations swiftly dubbed by news outlets as "a song of ICE and fire". Fans of the series might do well to remember Tywin Lannister's quote on Kings, then, with nationwide "No Kings**" protests planned for Saturday. As pointed out last month, this has to be a backhanded acknowledgement of sorts! This, of course, happens to be a pretty-obvious mirror of the socialist rebellion that LKY had to face early in his career, which soon had the FBI Director warning rioters that they would be jailed if they assaulted his officers. The situation seems to have stabilized somewhat after GEOTUS deployed the National Guard, and without having to arrest Democrat politicos (and enablers), in yet another flourish of strategic nous. Well, he did write the book on the subject after all, as we shall see! [*The other one didn't last very long.] [**Then again, the original L.A. riots started because of one.] Books Of The Art - Cambridge Dictionary  孙子兵法, 川子(交)易经! [N.B. Translation of couplet: The world laughs at me for being too mad; I laugh back at them for not seeing through (my cunning plan)] (Sources: amazon.sg, and again) In the realm of grand strategy, but one name has been preeminent since antiquity: that of Sun Tzu, legendary author of The Art of War, that timeless treatise that has stood unequalled in the field for some two thousand and five hundred years. One should not discount other celebrated contributors, certainly: Carl von Clausewitz and his Vom Kriege have oft been raised as the Western equivalent to Sun Tzu; stretching the definition a little, we have storied schemers such as Machiavelli and Richelieu, who inspired later generations of strategists, theorists and practitioners such as Bismarck, Talleyrand, Mearsheimer and Mao. The Art of War's position at the head of the canon remained essentially unchallenged circa 500 B.C., however, until its spiritual sequel The Art of Deal was published in 1987. The direct Mandarin translation of The Art of Deal (交易经), as it happens, literally references another classic, the I Ching (易经). To distinguish the modern masterpiece from its older and lesser cousin, it is referred to as 懂王易经 (King Dong***'s I Ching) in academic circles, as opposed to the slightly-outdated first edition, 文王易经 (for King Wen of Zhou). Properly put, The Art of Deal is a brilliant syncretic fusion of the pragmatic (Art of War; e.g. "a little hyperbole never hurts", building upon the dictum "all warfare is based on deception") and the abstruse (I Ching; e.g. "keep [your] balls in the air"); like yin and yang, this interplay between the mundane and the mystical feeds and uplifts both, within an inexhaustible cycle. And as to how these tomes have been applied to the Trade War chapter of The Greatest Game... relax, we're coming to that, any day now! [***The title itself implicitly praising his very large hands.]
GEOTUS did promise the opportunity for Americans (and, as it happens, anybody with access to NASDAQ or Coinbase) to become wealthy, after all - and for those who haven't figured the pattern out yet after this many repetitions... maybe finance is not quite their thing?  Honestly, it's fairly entertaining to watch! [N.B. A little kayfabe goes a long way, especially with foreign guest stars!]
- U.S. Secretary of Defense Pete Hegseth, closing remarks at the 2025 Shangri-La Dialogue in Singapore A scarce few months ago, Hegseth had been panned for not being able to name a single ASEAN country, so it was honestly quite remarkable as to how he went on to deliver some of the most-incisive and insightful remarks from a U.S. delegate ever, at this annual Dialogue. In also asserting that "the United States is not interested in the moralistic and preachy approach to foreign policy of the past", he has moreover signalled an extremely welcome turn in America's attitude towards others. Appropriately, his speech also emphasized Strength (19 times, if primarily as a prerequisite for peace) and Respect (7 times, including a statement of "immense respect for the Chinese people and their civilization"), one supposes it is really time to move on to the Strategy section of our planned trilogy; but first, some additional commentary on the previous post, which may have broken this blog's readership records once more. On the subject of TRUMP and LKY, it should first be understood that any comparisons drawn are entirely factual - they are based on documented and accepted evidence. It is perhaps their interpolation - and the perspective born from considering said facts side-by-side - that makes the truths and realizations derived thus, hard to bear for some. This, it should be noted, is something that LKY was no stranger to. He was never afraid of confronting Hard Truths, after all, and where Grand Strategy is concerned, there is nothing more important than knowing the Truth, unpalatable as it may be (although whether one chooses to admit or reveal it later, is another matter) 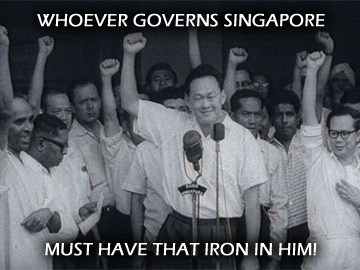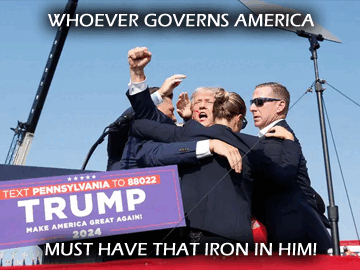 And what luck, the U.S. of America is gonna produce a lot more iron, with the 50% steel tariffs coming in! [N.B. LKY may be a little obsolete on the "game of cards" bit, though... but more on that next time.] (Sources: gmanetwork.com, businessinsider.com) With this said, it should also be established that I personally hold a deep respect for all LKY has done for Singapore, if not necessarily (all) his methods and views. The key point rests in maintaining internal consistency - if one lauds LKY (as good Singaporeans are expected to, I suppose), it would take incredible mental gymnastics and intellectual contortion to not do the same for TRUMP, given that TRUMP's major directives and policies are merely watered-down versions of LKY's. Going over the previous points in more detail, if we are to apply LKY's Operation Coldstore to the modern American context, this would be TRUMP mobilizing the FBI right before the general elections (with the acquiescence of the military, police and Supreme Court... perhaps in progress, fortunately) to arrest not only Hillary, but also Obama, Biden, Bernie, AOC and the Squad, dozens of other prominent Democrat leaders, and a few GOP dissenters such as Liz Cheney into the bargain, and imprison them for decades without any trial. Oh, there will be protests, but a few rounds of heavily-armed riot police (and state persecution of dissenters) should handle it. Continuing the analogy, all allowed television channels would become some variant of Fox News (which, as a former host, Hegseth may well be down for), and following a change of ownership, the New York Times would become a lot closer to the New York Post in outlook; after a few unlucky journalists are sued into oblivion, most of the rest should quickly understand the invisible OB lines, even without explicit legal directives. Opposition parties are, of course, given next to no airtime.  It's National Service Day! (Source: ChatGPT-4o) On education (which TRUMP is indeed actively reforming over in the U.S.), the official Republican Party-run kindergarten chain ("My Little Elephant" sounds cool!) soon dominates the market, becoming the only realistically-viable option for much of the working population. Primary and high schools teach a sanitized version of national history, with the humanities and inquiry on civil participation greatly diminished. Student unions and demonstrations are conclusively crushed, and non-compliant universities and colleges closed down (i.e. more a beheading, than a bend-the-knee thing). Well, there are benefits too. After the populace understands the futility of engaging in politics, productivity increases. Racial harmony is established by clamping down on anybody that steps out of line, and forcing ethnic quotas in public housing. Illegal immigration is a non-issue; they're simply jailed, whipped and sent back. Drugs aren't an issue either; guy has a kilo of weed? He's hanged. Streets are fairly clean too; caught littering from a vehicle? That's up to a year in the clink (that, and an army of sweepers). And yes, the (MRT) trains run on time. Mostly. The point here, I guess, is that LKY is a legendary-enough leader with enough strengths and accomplishments, that there is really no need to invent nonexistent virtues to burnish his living legacy. As an example, one LinkedIn post in response to the TRUMP-LKY comparison claimed that "[LKY] would not undermine democratic institutions", at which I involuntarily spit my drink all over my monitor. Friend! Angkat bola also not like that one, lah*! Are we even talking about the same person here?! The state of history and political education these days... [*Or, in standard English, even if you want to carry somebody's balls, it is still no good to spout complete utter poppycock**!] [**In LKY's defence, comments that "One is historic, the other is hysteric" aren't very accurate either; LKY may be many things, but "hysteric" doesn't quite fit.]  An inescapable conclusion. (Sources: nas.gov.sg, abcnews.go.com, figma.com meme) 朋友,懂王川普已经是李王光耀的仁慈版,希望你们能知福常乐吧!若要硬攀比这两个政治神话,懂王少了李王的几分狡猾冷酷无情,多了些温馨的皇者霸气!但这些差异到底是微不足道的,毕竟两人都是同类人,历代伟人,天才! Definitely, while the similarities far outweigh the differences - both LKY and TRUMP are known to part ways with former teammates once challenged, for instance, although as far as is known TRUMP hasn't thrown former allies and colleagues in jail yet - there are of course many small disparities. TRUMP staunchly promotes his own cultural and civilizational values, for one, whereas LKY has been more... eclectic in his principles. TRUMP has managed to keep his entire nuclear family (three wives, five kids, many grandkids) together and supportive of him (ok, fine, this is a bit of a low blow, and I sincerely hope that our Senior Minister mends fences with his brother soon) [To be continued, with reference to the Liar Game!  Well this is kinda ominous (Source: Liar Game #201 [final chapter]) ...maybe the author did draw inspiration for this manga from geopolitics, after all?]
 A mark of incomparable esteem; 真的受不起! (Source: channelnewsasia.com) It was with rapt interest that I watched United States Secretary of Defence Pete Hegseth address international dignitaries at the annual Shangri-La Dialogue, and my heart swelled with pride when he very diplomatically honoured the hosts by comparing TRUMP to LKY, in very kindly pointing out the many similarities and parallels between these two undeniably-great (and strong) men (as also noted on this blog back in 2017) The wise Secretary of Defence was indubitably exactly spot-on in recognizing both worthies as "historic men" possessed of "common sense and (grounded in) national interests (i.e. America/Singapore First)", and if anything Hegseth's flattery - in placing the President of the only universally-recognized superpower on a par with the leader of a pretty-successful, but ultimately minor city-state - felt slightly excessive. Ironically, there would be slightly-emotional vehement objections on certain local subreddits, and it was left to the less-censored EDMW forum to be more objective (as usual*) in discussing Hegseth's assertions. Consider:
As it is, since our government has not charged Hegseth under the Protection from Online Falsehoods and Manipulation Act (POFMA), one supposes the U.S. Secretary of Defence's statement on TRUMP and LKY to be fundamentally true, which I personally reckon is about right. Our new Defence Minister has also clarified that Singapore is not trying to balance anybody, and that the country is just a (open and inclusive) platform for dialogue. One supposes this a clever move - any smug indications of trying to play both sides don't seem likely to go down well, with both of the actual sides in The Greatest Game! And to close off, to any American friends who may be perusing this blog - if you happen to be of the (standard mainstream media) mind that LKY is, indeed, a more effective leader than TRUMP - and that he should therefore take a leaf out of LKY's book - well, you guys may yet get what you wish for! [*As the saying goes, EDMW is smart people pretending to be stupid, while r/singapore Reddit is... er, not so smart people pretending to be smart.] [**That said, refocusing universities towards hard science and technology with a view towards Cold War II, is entirely rational; given that Rubio has confirmed that Singaporean students can still submit visa applications, one imagines that the recent mass revocation of student visas was (again) aimed largely at China - who have been improving greatly in that department, by the way. Not that the liberal arts has exactly taken root locally, what with Yale-NUS being unceremoniously shut down following yet another Palestine-supporting convocation speech, and maybe a few dicey questions too many. The college then caught a furor for destroying hundreds of books before being found out, perhaps a sign of how much actual knowledge is valued here.] [***While I do have some sympathy for the downtrodden and/or discriminated, it is difficult to escape much of (officially-sanctioned) DEI as a power grab, these days. As an example, if one accepts the right of individuals to self-identify, the gulf in treatment between transsexual people (must be accepted without question, fine) and (sincere) transracial people (denigrate due to supposed cultural appropriation, because I guess their feelings aren't valid in this case) only suggests that not all social constructs are created comparably oppressive...]
陈年往事 青年不再 红颜佳人 随缘问天 The tune sounded familiar when it popped up on Spotify...
The Greatest Game has seen a temporary ceasefire with America kicking the Chinese can for another 90 days about May 12th, and putting the European Union on an early-July clock. Notably, this was declared after the E.U. specifically requested "respect" after the U.S. had dangled 50% tariffs beginning June, in keeping with the "Strength, Respect, Strategy" theme identified previously. Concurrently, after the local elections concluded without any real surprises, our Prime Minister has observed "major world powers reassessing strategies", and emphasized that "Singapore... cannot afford to be passive" at his swearing-in, again basically matching the analysis offered here at the start of May. Further dissection of said overarching strategy will have to wait a little longer, though, pending some recaps: Strength, Again The previous post had covered the historic election of the Lion of America, Pope Leo XIV, and it can hardly be missed that the original Leo was the first of just three popes (from a total of 267 thus far) to be acclaimed Great; given this, one can hardly avoid recognizing the connotation of Making (The Papacy) Great Again, despite misleading media efforts to paint the staunchly-conservative pontiff as "anti-right". Probably more strikingly, the new Pope Leo's maiden blessing would refer to the "weak (but always courageous) voice of Pope Francis" in praising his predecessor, which on second thought sounded somewhat odd - was the focus on "weak" truly necessary here, even considering the Church's sometime appreciation for the meek? This would have to be considered a bit of a diss from just about any other sovereign leader, and it may be telling that the Vatican would soon disavow widespread (fake) social media posts claiming that the new Pope had said that "A leader who mocks the weak... is not sent by God". And, speaking of (deep-)fakes... You Read It Here First None of this is real The late-April projection on Hollywood under threat had seen GEOTUS mull a 100% tariff on foreign films barely a week later, which received its fair share of industry support. Not that this is likely to stop the A.I. tide, however, with Google answering China's Kling with their Veo 3 video generation service - plus accents. Frankly, whoever wins, human actors are probably gonna lose, what with million-dollar advertisement shorts looking well within their capabilities already. Sure, A.I. videos still have their flaws - note the unconvincing waving (0:08), foreground/background confusion (0:58), skipping footsteps (1:26) and inconsistent character appearances (2:14) etc. in the NK Fellowship MV, for example - but many of these can conceivably be mitigated via clever framing and post-editing. Facial deepfakes have for one gotten so convincing that the U.S. House of Representatives recently passed a bipartisan bill targeting them, and one imagines mainstream virtual actors not being all that far away, what with deceased former stars routinely being resurrected. Related to this, the U.S. has also uncovered illegal smuggling of NVIDIA chips to China back about late February in conjunction with the local police, about a month after it was predicted here (again), but it's not as if deductive logic and talking sense is appreciated nowadays... |
||||||||||||||||||||||||||||||
 Copyright © 2006-2025 GLYS. All Rights Reserved. |
||||||||||||||||||||||||||||||






