




|
| |
|
| |
|
|
|
|
|
TCHS 4O 2000 [4o's nonsense] alvinny [2] - csq - edchong jenming - joseph - law meepok - mingqi - pea pengkian [2] - qwergopot - woof xinghao - zhengyu HCJC 01S60 [understated sixzero] andy - edwin - jack jiaqi - peter - rex serena SAF 21SA khenghui - jiaming - jinrui [2] ritchie - vicknesh - zhenhao Others Lwei [2] - shaowei - website links - Alien Loves Predator BloggerSG Cute Overload! Cyanide and Happiness Daily Bunny Hamleto Hattrick Magic: The Gathering The Onion The Order of the Stick Perry Bible Fellowship PvP Online Soccernet Sluggy Freelance The Students' Sketchpad Talk Rock Talking Cock.com Tom the Dancing Bug Wikipedia Wulffmorgenthaler |
|
bert's blog v1.21 Powered by glolg Programmed with Perl 5.6.1 on Apache/1.3.27 (Red Hat Linux) best viewed at 1024 x 768 resolution on Internet Explorer 6.0+ or Mozilla Firefox 1.5+ entry views: 2176 today's page views: 441 (23 mobile) all-time page views: 3832794 most viewed entry: 18739 views most commented entry: 14 comments number of entries: 1279 page created Wed Jul 22, 2026 01:53:55 |
|
- tagcloud - academics [70] art [8] changelog [49] current events [36] cute stuff [12] gaming [11] music [8] outings [16] philosophy [10] poetry [4] programming [15] rants [5] reviews [8] sport [37] travel [19] work [3] miscellaneous [75] |
|
- category tags - academics art changelog current events cute stuff gaming miscellaneous music outings philosophy poetry programming rants reviews sport travel work tags in total: 386 |

| ||
|
Following hot on the heels of Google+, Google has released Search By Image (GSBI), which lets users now search using pictures. Got a historically relevant scene that you can't put your finger on? Baffled at what minor landmark was taken in your collection of holiday snapshots? No problem, just upload it and let Google figure it out. Eh wait, isn't that exactly what TinEye does, as mentioned here, like, a year and a half ago? Let us evaluate the search and leave what this means for TinEye till a little later. First up are some specimens from my European travels [N.B. Images of search results as presented below were rearranged for succinctness]:  GSBI cleverly ignored alvin's head at the bottom left and correctly identified the tower as belonging to the Plaza de Espana in Seville. Trying again with a wide shot, GSBI again got it right:  But wait ah, the visually similar images are not of the Plaza, but of random buildings/monuments sticking out into a bluish sky (I suppose there are many of these in existence). So how did they make the positive identification? Turns out that somebody took a shot (inset, below) at almost exactly the same angle as me (main picture, below), so much so that it was designated a "matching image" by GSBI:   Less famous curiosities like a statue of Don Juan (above) fared worse, with totally irrelevant results. It should be stated the only other image of it that I could find on the web after a brief (textual) search resides on a now-defunct blog, but I was slightly puzzled at the seeming dearth of bronze sculptures standing before trees in the entire world. There are of course a ton of experiments that could be done to try and pry out the general algorithm used, but let's be content with just a couple more. Whatever the algo is, it appears great at detecting regions within images, as this search using Paul Scholes shows: 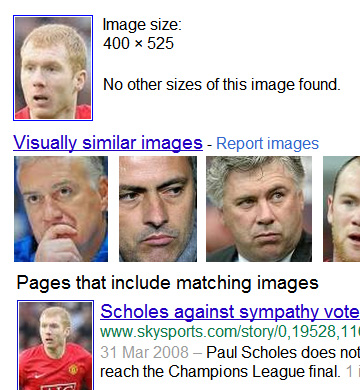 The matching image was, in fact, where I cropped the test image from. I found it slightly suspicious that no ginger-haired guys were deemed more similar to Scholes than (from left to right) Deschamps, Mourinho, Hiddink and (wait for it) Rooney, though! This led me to suspect that when returning "visually similar" images, GSBI uses more than pure image data. To test that, I simply flipped the cropped Scholes photo horizontally, such that now he's looking to the right, and resubmitted it: 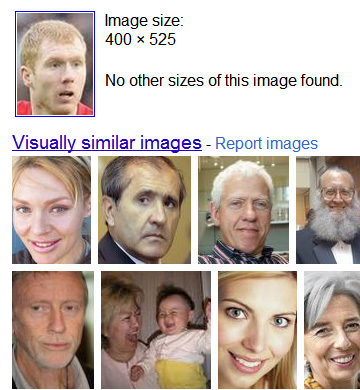 Who would have thought that it would have made that much of a difference? All football-related mugs are gone, replaced by a slew of random people (with a pensive-looking George Bush in the third row down). And how is all this done? Someone new to all this might reason that similar-looking images can be detected by resizing them to the same dimensions, then summing the difference between each pixel. This very simple idea is actually not all that unreasonable, and certainly works, albeit under rather limited conditions. Quite apart from the issue of matching is the issue of speed; even a low-resolution image routinely contains hundreds of thousands of pixels, and this can add up fast. One simple hack is to reduce (desample) the image by reducing the resolution, and doing initial lookups on such "fingerprints", which would allow non-matching images to be quickly discarded. But what about subimages? The most obvious way would be to resize the image to various scales, and test it against each image at each possible approximate position. Unfortunately, the number of combinations swiftly multiplies, and if we add considerations like rotation into the mix, this can be shown to quickly become impractical (today at least). A pretty good and publicly-known algorithm, Scale Invariant Feature Transform (SIFT), that addresses each of these concerns has been out in the open for over a decade. Those interested in the details can read the Wikipedia article above (or even the original paper), but I believe the general idea is that key features are first detected (so that effort is not wasted on say the background) and transforming these key feature (sets/clusters) into a universal space to accomodate orientation. So does GSBI do that? Interestingly, rotating the cropped Scholes image by a couple of degrees returns the same output as the unrotated copy, and rotating the face by as much as 45 degrees still maintains much the same results, although the source is no longer acknowledged as a "matching image". Astoundingly, rotating 180 degrees more (such that Scholes is now upside down), we still get "manchester united" as the best guess, with Rooney as the most visually similar (to an upside down face? I know he's no great looker but...) 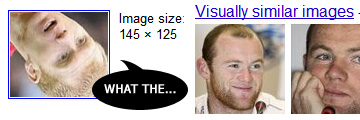 Recalling that merely flipping horizontally breaks the recognition, one might suspect that whether or not GSBI uses SIFT (or an adaptation), they happen to have the same responses towards some classes of transforms (i.e. rotation) and not others (i.e. flips) [N.B. It is trivial to adapt the algo to accommodate this if desired]. Additionally, GSBI appears to be ace at detecting major features too - try a simple, clear drawing (like this Hello Kitty), and you'll notice that GSBI returns many similar-but-not-quite examples, with variations such as:
This is just one step in the entire process, and who knows what else they have done? Perhaps they have used other measures such as histogram or Fourier transform frequency running in parallel? Who knows? The point is that TinEye may well find it very difficult going forward from here. Can their algorithm outperform Google's significantly to carve out a niche? I'm not sure. Will their index of images (nearly two billion at least count, it has to be said) allow them to stay competitive? Rather unlikely, given that a random single-digit search on Google Images already returns on the order of sixty billion images. A few days ago, Google searching for the next Google hit the news, but much of the time it would make more sense for Google to simply reimplement the idea themselves. Given that they have much of the world's top talent oozing out of that ears, that can't be too farfetched. It seems to come down to having something so wonderful that nobody at Google (or some other big company) can replicate it speedily, having it so out of left field that they don't recognize its potential, or small enough that they don't bother or feel nice enough to ignore. And good luck with patents too, as df noted on Facebook recently. While of course a good idea, figuring out what is a minor adaptation of a patented idea, and what is actually original enough, is not easy. A famous example of a likely too-broad is Amazon's One-Click patent, though that has nothing on this. Heck, a local company got peanuts despite patenting the ThumbDrive, with many manufacturers basically ignoring their claims - maybe even legally, since patents aren't international by default.  Ms Robo feels that they can do better I'll be on reservist the coming week, and taking this attitude with me:  Wish me luck (Source: Somewhere on the Internet) Next: Anatomy of a Massacre
Trackback by Hack Kings Road
Trackback by Pick 6 Leak Proof
Trackback by how to hack wifi
|
||||||||||||||
 Copyright © 2006-2026 GLYS. All Rights Reserved. |
||||||||||||||




