




|
| |
|
| |
|
|
|
|
|
TCHS 4O 2000 [4o's nonsense] alvinny [2] - csq - edchong jenming - joseph - law meepok - mingqi - pea pengkian [2] - qwergopot - woof xinghao - zhengyu HCJC 01S60 [understated sixzero] andy - edwin - jack jiaqi - peter - rex serena SAF 21SA khenghui - jiaming - jinrui [2] ritchie - vicknesh - zhenhao Others Lwei [2] - shaowei - website links - Alien Loves Predator BloggerSG Cute Overload! Cyanide and Happiness Daily Bunny Hamleto Hattrick Magic: The Gathering The Onion The Order of the Stick Perry Bible Fellowship PvP Online Soccernet Sluggy Freelance The Students' Sketchpad Talk Rock Talking Cock.com Tom the Dancing Bug Wikipedia Wulffmorgenthaler |
|
bert's blog v1.21 Powered by glolg Programmed with Perl 5.6.1 on Apache/1.3.27 (Red Hat Linux) best viewed at 1024 x 768 resolution on Internet Explorer 6.0+ or Mozilla Firefox 1.5+ entry views: 1214 today's page views: 1271 (26 mobile) all-time page views: 3833624 most viewed entry: 18739 views most commented entry: 14 comments number of entries: 1279 page created Wed Jul 22, 2026 04:46:46 |
|
- tagcloud - academics [70] art [8] changelog [49] current events [36] cute stuff [12] gaming [11] music [8] outings [16] philosophy [10] poetry [4] programming [15] rants [5] reviews [8] sport [37] travel [19] work [3] miscellaneous [75] |
|
- category tags - academics art changelog current events cute stuff gaming miscellaneous music outings philosophy poetry programming rants reviews sport travel work tags in total: 386 |

| ||
|
Having just gotten home from campus, I was taken aback to find Mr. Robo laid out before the front door. Me: Erm, why are you prostrating yourself, Mr. Robo? Mr. Robo: *Not raising his head* I'm sorry! I'm sorry! It failed! Please don't euthanize me! Me: Huh? Wait... did Mr. Ham have anything to do with this? Mr. Ham: Hey, I was just tryin' to motivate our research asset 'ere to greater pro-duct-i-vity levels, see. Me: Bad hamster! Bad hamster! Mr. Ham: 'ell now, I was jus' helpin' out. 'M being nice all'dy, ain't even pulled out my Cult Leader techniques like threatening 'im with what e's gettin' after 'e dies. Me: Great, you've even picked up the accent from your overseas Sect Expansion Exchange. Shoo now, go find something else to do. *Turns to Mr. Robo* And what's the matter? Mr. Robo: *sniffles* Well, I was just following on from our character recognition investigations. I first finished coding the distortion correction as mentioned a month or so ago. That bit was rather successful, if I say so myself:  The next step was to verify whether the SVM model we built was adequate, and to check that, I manually segmented 50 Google CAPTCHAs into their individual characters, like this:  I then ran the 450 characters gathered thus through our SVM model, and the results weren't good enough: 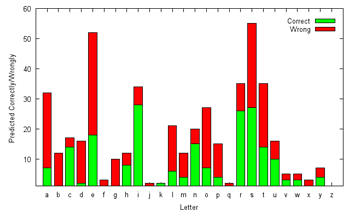 *Nervously* What this basically says is that the recognition success rate is only around 45% for distortion-corrected characters (about 40% without), and that this varies by letter - for example, "i" and "r" have a relatively high success rate, while "b" and "d" are predicted especially poorly. I've generated a 38-page compilation with the details, but my reading of what has happened is that despite our efforts in introducing distortions into our training data, they were still insufficient to encompass the actual CAPTCHA variations. Me: In a way, this can be understood - MNIST for instance used 6000 training instances for each digit, there were only ten digits in total, and as far as I know the digits were not deliberately made less legible, as for CAPTCHAs; in contrast, we used only 1000 training instances for each of 26 letters, with a relatively small selection of fonts which might not have reflected those actually used in the CAPTCHAs. But from another perspective, 45% isn't completely out of whack - it's roughly what we got on testing on the decorative fonts, and about ten times better than pure chance (3.8%), or four times better than guessing the most common letter. Heck, I ran the suitably-resized characters through Tesseract, which gave like 36%. Mr. Robo: Well, if you put it that way... Me: But yes, it isn't good enough. You might as well reveal what the next step would have been, since it's kind of obvious anyway. Mr. Robo: Yes, about that. I would then have attempted to extract letters from the CAPTCHAs, using an idea which has had many names in its various forms - scale-space representation, pyramidal decomposition, hierarchical modelling... but basically it's just examining many subdivisions of the CAPTCHA, discovering the most plausible letter candidates, and stitching the findings back into an answer. Mr. Ham: I call it Shoot-Shoot-Shoot, because what it does is just shooting lines down to cut the image apart. Catchy, yes?  Mr. Robo: It did make some sense. Me: Don't be influenced by him! Mr. Robo: Sorry. Here's an example, using our actual model results:  Where the subimages correspond to high recognition probability scores, they are coloured, in red for probabilities greater than 0.9, and purple otherwise for probabilities greater than 0.75. Testing speed, mentioned before, is important due to the number of subimage checks required - for now, it is still manageable, with the 700-odd subimages taking just a couple of seconds to run through (the animation is slowed for viewing purposes) As can be seen, most of the actual letters do result in high probabilities, other than "i", which is consistently mispredicted as "j" here. The problem is that quite a few non-letters have high probability responses too:  Well, ok, there's the shadow of a "u" there... These rather unreasonable false positives mean that it is unlikely that the method will work as of now, since it would be extremely hard to distinguish between true and false letter candidates, though some of the CAPTCHAs were nearly solved, but always tripped up by the stray letter or two; our search for a black box that, when given a candidate image, either rejects it as a non-letter or correctly identifies the letter it represents with extremely high probability, thus continues. Me: I might as well mention here that I did manage to get a second set of Google Captchas which exhibit the characteristics as mentioned here, i.e. they contain between 5 to 8 letters only (average 6.48, strongly suggesting that number of letters is uniformly distributed), and not the 8 to 10 letters we got for our first dataset. Spent most of Saturday afternoon solving the 2000 of them twice. The intra-rater reliability was 97.75% this time, up from 92.85%, as expected with fewer letters, with the estimated single-letter recognition rate also increasing from 99.18% to 99.65%, though that's not saying too much. Maybe we should help the research community by making both datasets publicly available, maybe as GROBO-1 and GROBO-2? Mr. Robo: There's a small problem with that... Mr. Ham: I've bought over the rights to them. Mr. Robo: I was hungry, and he had some very tasty-looking sunflower seeds, so... Me: ...I suppose that's about it on this for now. There're a couple of things we could do, including simply adding more data with more varied distortions to the model (which might however adversely affect prediction time), but all this will have to wait. Got a thesis to start thinking about seriously, along with other interesting challenges - the CAPTCHAs aren't going away, and the general problem has stymied some of our best minds for a long time, after all. Mr. Robo: Um, on this note, Google Handwrite for smartphones has just launched. Me: Great, one more idea scooped. Not that it was that new actually, Palm OS has had Graffiti for years. In any case, they're still limited to block letters for the most part, so there's still space to explore. Onward and upward! Next: Olympic Musings
Trackback by Chemist Direct Healthcare Products
Trackback by restaurant stakeout
Trackback by sex cam girls
Trackback by bang my wife
Trackback by loans for people with poor credit
Trackback by weight loss meal plan
|
||||||||||||||||||||
 Copyright © 2006-2026 GLYS. All Rights Reserved. |
||||||||||||||||||||




