




|
| |
|
| |
|
|
|
|
|
TCHS 4O 2000 [4o's nonsense] alvinny [2] - csq - edchong jenming - joseph - law meepok - mingqi - pea pengkian [2] - qwergopot - woof xinghao - zhengyu HCJC 01S60 [understated sixzero] andy - edwin - jack jiaqi - peter - rex serena SAF 21SA khenghui - jiaming - jinrui [2] ritchie - vicknesh - zhenhao Others Lwei [2] - shaowei - website links - Alien Loves Predator BloggerSG Cute Overload! Cyanide and Happiness Daily Bunny Hamleto Hattrick Magic: The Gathering The Onion The Order of the Stick Perry Bible Fellowship PvP Online Soccernet Sluggy Freelance The Students' Sketchpad Talk Rock Talking Cock.com Tom the Dancing Bug Wikipedia Wulffmorgenthaler |
|
bert's blog v1.21 Powered by glolg Programmed with Perl 5.6.1 on Apache/1.3.27 (Red Hat Linux) best viewed at 1024 x 768 resolution on Internet Explorer 6.0+ or Mozilla Firefox 1.5+ entry views: 591 today's page views: 1251 (25 mobile) all-time page views: 3833604 most viewed entry: 18739 views most commented entry: 14 comments number of entries: 1279 page created Wed Jul 22, 2026 04:32:56 |
|
- tagcloud - academics [70] art [8] changelog [49] current events [36] cute stuff [12] gaming [11] music [8] outings [16] philosophy [10] poetry [4] programming [15] rants [5] reviews [8] sport [37] travel [19] work [3] miscellaneous [75] |
|
- category tags - academics art changelog current events cute stuff gaming miscellaneous music outings philosophy poetry programming rants reviews sport travel work tags in total: 386 |

| ||
|
Given the short lull, I thought I'd delve into the promised piece on journal peer-reviewing, which I believe is a lesser-articulated side of the business of academia. Just to clarify, such peer-reviewing is distinct from the "book/play/movie reviewing" that laymen might be more familiar with, if only because such reviews for public consumption generally presuppose that the work in question has already been accepted and released by some publisher or producer (such post-reviews remain not uncommon in the humanities, though, with shorter pieces often akin to advertising copy, and longer ones a kind of Cliff's Notes, or even qualifying as original literary reinterpretations in their own right) Whereas in academia, peer-review serves as a roadblock to publication; fail it, and the paper does not get published (in the intended journal/conference, at least). Of course, journals no longer serve as a necessary middleman for distribution purposes nowadays - anybody can upload their paper in its full-colour glory onto open-access repositories such as arXiv, their own webpage or Google Drive in a pinch, and have it instantly available to anybody with an Internet connection. Journals are now primarily gatekeepers to prestige. Any crank can self-host his complex ramblings on 6-D space-time cubes; get the same work into, say, Science, however, and plenty of reputable physicists will be bound to give the theory a second look. However much some intellectuals might dislike it (we've mentioned Higgs' self-assessment of his survivability, to which might be added a Turing laeurate in databases noting that he had gotten his Ph.D. with zero publications in 1971, and tenure at Berkeley with five - which is what good Ph.D. applicants might have, nowadays), this is what the "publish or perish" academic game has come to. If one doesn't publish - and keep publishing - in reputable journals, there will often be someone hungrier who's managing to. Thus the treadmill turns. Arguing from the other direction, requiring publications might not be wholly unreasonable, since producing and disseminating new knowledge is the main job of (research-track) academics, after all. Further, one gets the impression that output of an appreciably-high level can be consistently achieved in certain fields, such as medicine, where even negative results on comprehensive-enough studies are inherently extremely valuable. In others, such as applied computer science, rapid turnover aids in advancing the field as a whole - for example, instead of trying to work out every last theoretical justification behind a new algorithm into the perfect manuscript over years, it's often rather more beneficial to push out a good-enough prototype, and allow the community to build on it. Tiers & Demand  It tends to then repeat the next level down (Original source: imgur.com, more like it) While genteel academic sensibilities might not allow it to be openly belaboured, I hope that it is no secret that not all journals & conferences are created equal (which, frankly, should really be communicated to fresh-faced graduate students very early on, lest they waste their efforts). Quite broadly speaking, there tends to be a few elite journals for each field: C/N/S for the natural sciences, the Big Four (or Three, or Six, depending on who you're willing to mortally insult) in medicine, and the Top Five so frequently bandied about on the anon Economics Job Market Rumors (EJMR) forum, who have distilled tenure standard benchmarking into a fine art (e.g. whether one Top5 paper and two "top fields" the next tier down, is equivalent to five "top fields", but they're economists, so what did you expect? N.B. EJMR has taken to displaying the Bitcoin exchange rate on their front page [further also expressed in terms of mean UK Assistant Prof annual salary units, i.e. 1 UKAP], so maybe they're more in-tune with reality than I thought) The point here, at least towards the topic of reviewing, is the acceptance rates. For the elite "glam mags", only somewhere from 3% to 10% of initial submissions are ultimately accepted, at least for the fields mentioned above (natural sciences, medicine, economics) - and one supposes that the vast majority of these are serious efforts. The next tier down tends to have acceptance rates up to about 20% (though with more variation, since some subfields can get very picky), which is also about where your top computer science conferences tend to reside. Reputable field journals/Rank-2 CS conferences tend to reside within the 20%-40% acceptance rate band, megajournals (e.g. Scientific Reports, PLOS One) accept over half of their submissions (there are some gems in that volume), before we get to the... dodgier pay-to-play/predatory underbelly. Consider now that most any respectable journal/conference tends to call for three or more peer-reviewers per submission nowadays, and that many papers are rejected (possibly multiple times, generally from the most prestigious venues downwards) before finding a home, the unavoidable conclusion is that there is a heck a lot of reviewing to be done. To be sure, this is somewhat mitigated by desk rejects (where the editor straight-out denies clearly unsuitable/bad submissions, also beginning to be implemented in some form at A.I. conferences, due to a worsening lack of qualified reviewers brought on by the area's sudden explosion in popularity), but it probably remains a good rule of thumb that for every paper one submits as the first author, one should expect to review about three in return. To Review Or Not To Review? I have read somewhere that an academic's attitude towards reviewing passes through three stages: initially, elation and not some apprehension at being requested to provide one's first few reviews, from the (slight) recognition of being "part of the gang", which tends to come with a worry that one might not be qualified to pass opinion on possibly far more-accomplished scholars. This then slowly turns into a sense of duty, as the freshly-minted junior professor/fellow realizes that reviewing is a necessary part of the job - as in football or basketball, no referee, no game. That said, he soon realizes there is essentially zero fame or recognition, unlike in sports where you can get an occasional Pierluigi Collina; it is no surprise then that senior big shots can come to think of reviewing as a bit of a drudgery, and pawn their assignments off on their underlings (that said, early-career guys supposedly do a more thorough job anyway) Before continuing, just to establish some bona fides: over the past six years, 157 items from 44 journals, three recurring conferences and one grant body have crossed my desk for peer-review, by my own count (does not include reviews of revisions unless resubmitted to a journal within the same family, includes a few unofficial consultations) - so forgive me if I gather I'm not completely useless at the gig. Which brings us to the original question, on whether a newbie should accept review requests. I'd say yes - if the paper lies somewhere within or adjacent to his area - because the worst that could reasonably happen is that the editor thinks that the review is not up to acceptable standards, in which case he shrugs and simply invites another reviewer (which probably happens to everyone). Of course, if it's obvious that the paper is too far outside one's competency (as happened to yours truly for a couple of extra-heavy mathematical expositions), there's no shame in (rapidly) informing the editor too, to allow for reassignment. The exception would then be clearly-predatory for-profit journals, but I have to confess to having a soft spot for less-prestigious niche outlets, and will generally try to review for them at least once, if it looks like a reasonable effort. The Golden Rule While reviewing conventions may differ greatly between various fields, my experience from dealing with papers situated every which way between my main professional specialties of computer science (particularly computer vision & A.I.) and translational medicine (mostly relating to ophthalmology, but also various imaging fields), as well as pinch-hitting for a fair mix of interdisciplinary material, has convinced me that there is at least one unifying principle for good peer-reviewing, regardless of the field: the overriding intent of a review should be to result in an improved contribution to science. Now, I've probably been identified as Reviewer #2 at some point, the (unintentionally) adversarial nitpicker who continually sweats the small stuff and lists out all the minor spelling and grammatical errors. To be entirely honest, looking from the author side in, I can fully understand the attraction of a reviewer that for once unreservedly says, "This is brilliant work, accept for publication immediately without hesitation!" Alas, such reviews are ultimately Not Good*. It could, definitely, be true that the manuscript in question is actually pristinely beyond all reproach; however, more often than not, the other reviews would suggest that there were, in fact, a number of issues that could bear to receive attention. If so, it would then look like the entirely-positive reviewer had simply fobbed the authors off with faint praise; indeed, there is no evidence that the reviewer respected them enough to perform the basic courtesy of actually reading and trying to understand the manuscript (beyond the abstract, anyhow), and attempting to rigorously deconstruct and critique the proposal. In proper science, there is no greater snub than this; it is on a par, I think, with Pauli's contemptuous "not even wrong". [*Actually, there is occasionally insult heaped upon snub, with the request to cite a not-even-remotely-related paper following the effusive not-a-review.] The Golden Rule of reviewing, then, would be this: if you were teleported to a conference table with a copy of the review, and the authors of the paper were teleported to the other side of the table (might be tricky for certain large genetics and particle physics collaborations, though), would you be able to look them in the eye and read out all the points raised, and actively defend them? In other words, although reviewers are traditionally protected by the veil of anonymity, they should nevertheless strive to write their reviews as if their name and reputation would be attached to it (as some venues are now allowing, albeit with uneven uptake) [N.B. As a related aside, I'm not quite sure what to make of certain journals allowing "non-preferred reviewers" to be suggested; personally, that sounds like an invitation for some fun assignment trolling] Basics  Maybe a repeat, but what the heck (Original source: justinholman.com) Well, one's taken the plunge and clicked on the "Accept Review" button, and the PDF file has been downloaded, bringing with it the promise of another burnt weeknight. What next? Before beginning, it's usually a good idea to check what the editor expects (i.e. the reviewing form). Some of these forms are far more structured than others, for instance with guiding questions such as "Are the methods correct", "Is the level of English acceptable", etc. Interestingly, in my experience, the higher-tier the journal, the more free-form the review is allowed to be. This kind of makes sense, actually - for these journals, the initial triage-by-editor would have eliminated submissions with obvious problems. Any remaining critique would thus be expected to be on relatively obscure and subtle concerns, which sums up to a more bespoke approach for every paper. What's obscure to one reviewer, that said, might be bread and butter to another, which as it happens is one of the motivations for recruiting multiple reviewers (and therefore, perspectives), especially for papers that touch on more than a single field. Take for example your standard machine learning (ML) in biomedicine paper, nowadays. I daresay I might be slightly more equipped to comment on the application of ML in some depth, but when it comes to the underlying mechanisms of the disease in question, an actual medical specialist would have to be called for. For the broader overview, you'd probably want a senior fella who's been involved in similar studies, so on and so forth. Certainly, it could be difficult to find an individual with expertise in all aspects (but it can't hurt to try and pick up outside stuff as one goes along, by reading what the rest of the reviewers had to say. This also gives an idea if one's reviews are roughly good-enough) The Review Proper Here, I attempt to describe a broad methodology that has evolved over the years:
Tattling One practice that most journals/conferences appear to allow for, is for a peer-reviewer to provide "privileged" comments to the editor only, that is hidden from the more-public main review that is returned to the authors and other reviewers. Personally, I am in principle generally opposed to such secret justifications, since the primary purpose of a review, in my mind, should be to provide feedback and opportunities for improvement (of course, the editor/other reviewers may have different ideas on what constitutes improvement, but the point stands). Obviously, hidden comments cannot provide that, and there are few experiences more frustrating than receiving three gushing and/or perfunctory reviews with no substantial critique, and then somehow have one's paper rejected. Amusing Anecdotes/Caveats Given all the interest in medical (epidemiological) research no thanks to the ongoing pandemic, it may be timely to raise a couple of eyebrow-raising observations from my reviewing for some pretty-reputable medical journals (exact topics/subjects involved suitably modified to preserve anonymity) The first case involved, as part of one of the paper's main messages, a statement of the form "Teenagers that consume at least one egg a day are likely to have improved health outcomes" (actual line didn't pertain to teenagers or eggs, but you get the idea). Now, this happened to be the kind of broad assertion that the general public likes to take an interest in, and that, as a result, has seen intermittent attention in the mainstream press. In fact, the last such news article I recalled reading had claimed no health benefits from egg consumption, to the best of my memory, and as such I examined the given citation - from a pretty high-impact journal in the relevant field - out of curiosity. Indeed, its abstract suggested no benefits from a large study, confirmed by the main text. As such, there was nothing for it, but to inform the authors that their citation did not actually support their statement, as part of my review. To their credit, the authors acknowledged the discrepancy, and fixed it by providing a replacement citation to another research paper from a no less respected journal, that did support the hypothesis that eggs are good for teenagers. Understandably, I remain no more enlightened as to the value of an egg-based diet, but at least the forms have been obeyed. The second case involves an otherwise very impressive interventional study regarding a new treatment, that concluded with the main finding that said new treatment was significantly more effective than current standard practice, and that doctors might strongly consider adopting it. It has to be said that the analysis was, as far as I could make out, entirely competent, especially after the initial round of reviews. Part of the authors' response was the addition of many new figures, among of which was included a chart like this: 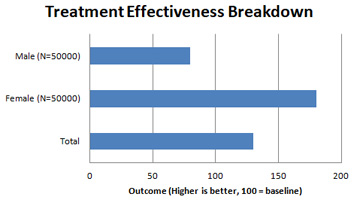 [N.B. The original was fancier, but this contains the gist of it] Now, this did entirely support their initial claim, that the proposed treatment improved outcomes in the general population by about 30%. What had not been explored, however, was that the benefits were unevenly distributed - in this case, far superior for females, but actually detrimental for males. Far be it for me to discourage such informative disclosure, but I could not help but communicate to the authors in the next review round that, acktually, this variance in outcome might be, like, kind of important to emphasize somewhere in the text? In this case, sadly, it seemed to have fallen between the cracks, and as such the (quite true) assertion made in the published abstract and conclusion remains that "new treatment works (for everyone implied)!"; well, one hopes that practitioners serving all-boys schools and male-dominated professions like the army read the paper carefully, then. Passing The Verdict For all the care that may (or may not) have been put into crafting the review, one suspects that what many authors (and perhaps some editors) are most interested in, would be the final recommendation - in or out?  That could mean accept, by the way (Source: tenor.com) Here, there is a divergence between journals and conferences from my experience, due to their fundamentally distinct natures. For most journals, there is no fixed time limit on the review process, and as such a promising-but-unpolished work can exist indefinitely in a state of "revise-and-review", until all involved are satisfied. Conferences, however, are held on a specified date, and as such there can be no expectation that submissions can be substantially reworked (e.g. with additional experiments); they have to be accepted largely "as-is". Thus, journals tend to offer the following recommendations:
Some journals might provide minor variations (e.g. minor revision with/without further review, revise/reject and resubmit, which some have suggested is meant to boost the journal's turnaround time/rejection rate and thus prestige), but these are the most common four options by far. The thing, however, is that "major revision" probably covers too much ground (it makes up the vast majority of my initial verdicts), because it encompasses everything from "superb paper, just needs a number of necessary clarifications" to "this should probably be rejected, but there's just nothing particularly wrong with it". One supposes that the editors have gotten used to teasing out these finer distinctions from the actual review text. For the computer science conferences that I'm more familiar with, in contrast, there's simply no time to be pussyfooting about, and reviewers tend to be asked to deliver their judgment on a quantitative scale. One popular formulation goes from 1 (trivial or wrong, will consider not reviewing for the conference again if accepted), to 10 (Top 5% paper, will consider not reviewing again if rejected), which is sometimes zero-centered (i.e. 0 is a neutral judgment, -3 is very bad, +3 is very good; conferences often like to remove the neutral option to force reviewers to take some stand, however small). Generally, these scores are considered together with reviewers' self-assessment of confidence (1: educated guess, 5: absolutely certain), to guide the program committee's decision. Being the quants that they are, not some few post-hoc analyses have been performed on how these scores affect acceptance decisions, and for all of various organizers' insistence that they consider reviews on their merits and are not bound by scores, evidence suggests that aggregate scores are very predictive of acceptance; which is in itself hardly objectionable, because the review process is meant to be objective, after all. However, experiments with parallel program committees have also suggested that there is also a large amount of noise in the reviewing process. In particular, for one top ML conference, it seems likely that a comfortable majority of submissions could plausibly have been accepted, the corollary of which is that "most (actually accepted) papers... would be rejected if one reran the conference review process". The response to this observation by more-ambitious researchers appears to have been: simply submit more papers. This makes a lot of sense when one considers that it tends to be far harder to generate a near-guaranteed shoo-in (which might not even be, if one gets a bad reviewer draw), than to crank out multiple merely-competent submissions. This has seemingly become a widespread-enough strategy/concern, that various top A.I. conferences have had to impose a hard limit on the number of submissions that any individual can be a co-author on. Handling Appeals (i.e. Re-reviews) Mercifully, it does get easier. For any single paper-under-review, that is. Ideally, the initial review should have covered all major points of contention; for myself, it's kinda bad form to drag a new argument out of nowhere, unless truly critical. Indeed, particularly for higher-impact venues, it's heartening to find how responsive authors can be, sometimes to the extent of running additional experiments (though they're also usually careful to state that these were added on request, given recent concerns about changing hypotheses/p-hacking [N.B. That said, "happy accidents" and retrospective data mining have been an integral part of scientific discovery, so the lesson here is not to ignore hunches, but to test them properly as an independent hypothesis]). Also, it's not that the authors have to implement all suggestions from all reviewers - which might be impossible anyway, since some might be contradictory; the main thing is to address them, which could be as simple as agreeing that it's a good idea, but might be left for future investigations (of course, depending on the severity of the critique, this may not apply) For conferences, there is often only a single response/rebuttal possible due to the deadlines, which has birthed specific advice as to how to make the most of it (in particular, try to clear up the biggest misconceptions, target and nudge borderline reviewers, possibly through peer pressure). That said, it's probably best for authors not to expect too much. The Future Of Academic Publishing As noted back in 2018 on the open-access "Plan S" (which appears to have been delayed again), even famously-naive ivory-tower academics are slowly coming to realise just how badly they're being ripped off by commercial publishers, who're mainly providing basic formatting and typesetting services nowadays - aside from historical prestige, that goes without saying. Still, even venerable journals (e.g. the BMJ) have shifted to more-transparent reviewing (and thus publication) processes, with open review now the norm for many top-tier computer science conferences. Whether this presages a wholesale shift towards LeCun's "stock exchange system" proposal, where independent reviewing entities can build their own reputation on providing high-quality service, remains to be seen... Next: Material Update
|
|||||||
 Copyright © 2006-2026 GLYS. All Rights Reserved. |
|||||||




